在银行等金融机构的信贷业务中,围绕存量客户的数据分析与价值挖掘,始终是客户管理体系的核心思想。针对存量客户群体的类型划分与画像描述,是实现客户价值评估以及精准营销的重要前提,也是业务创益增收的必要条件。
1、客户分类与画像场景
我们经常提到的客户分类与客户画像,是数据分析任务比较熟悉的场景,二者本质上都是对存量客户样本的数据分析,但最明显的区别是客户分类结果重在“宏观”上的群体类别,而客户画像结果旨在“微观”上的特征描述。换一句话来讲,客户分类可以不需要细节总结,客户画像可以不考虑类型划分。当然,客户分类与客户画像的关系也非常密切,先“宏观”分类再“微观”画像的应用思路,在实际业务场景中更为常见且效果更佳。在具体实践过程中,客户分类相比客户画像在实现方法上往往更为复杂,不是简单的通过描述性统计分析便得到样本分类,而是需要借助于相关业务指标或者模型算法。一种情况是结合实际业务理解,选取某个或多个维度指标作为分类依据,然后选取合适的阈值划分类型;另一种情况是依靠机器学习模型来训练完成,常见的主要为聚类模型算法,例如Kmeans、DBSCAN等。当客户群体完成分类后,可以针对每类客户群体,从某些业务解释性较好的特征着手,通过简单的描述统计值来刻画出客户分布的特点,这样便实现客户群体的画像。这里简单举个例子,假设有一批存量客户数据,特征为年龄、婚姻状况、教育程度、住房类型、月收入金额等字段,可以先通过Kmeans聚类模型对样本进行聚类分析,例如定义聚类数量K=3,则可以得到3个客户簇类,接着根据每个簇类样本群体,依次统计客户特征的均值与极值等,例如第1簇类群体,平均年龄为36岁,大多数已婚,教育程度平均学历为大学本科,住房类型多数为自置有按揭,月收入平均约为2万元等。这个分析与描述过程,可以认为是客户分类与客户画像有效结合,在实际场景中有很多类似的场景应用。
2、实例样本介绍与分析
为了便于大家对客户分类与客户画像的进一步熟悉与理解,接下来我们围绕具体的实例样本数据,来完成客户样本数据的分类与画像。本文选取的样本数据包含10000条样本与9个字段,部分数据样例如图1所示。其中,id为样本客户主键,income_type、city_level、consume_index、bankcard_count等为特征变量,label为客户贷后逾期表现(1/0代表是否逾期),具体的特征字典如图2所示。
由于字段income_type、city_level的取值类型为字符型,相关数值分布如图3、图4所示,此类特征在描述性统计过程中不便于数据分析,因此这里采用label编码方式将此类特征进行取值转换,具体实现过程详见知识星球代码详情。。在特征编码过程中,结合特征在实际业务的理解,赋予取值的比较关系,例如特征income_type(月收入等级),取值L1/L2/L3代表月收入依次升高,在label转化过程可以分别赋予1/2/3。
3、客户分类探索与实现
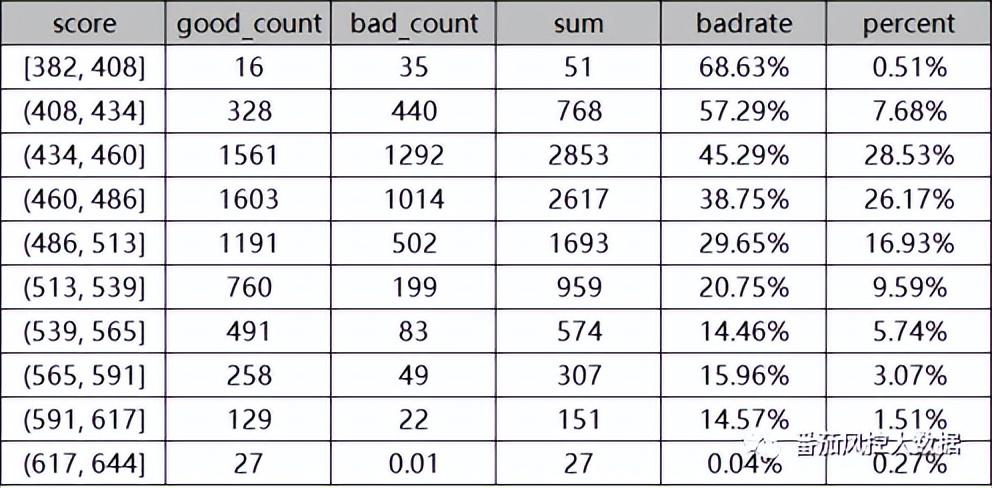
首先我们来对客户群体进行分类,这里不采用机器学习聚类算法来实现,而是通过某个业务解释性较好且区分度较好的特征来划分客户类别。从特征字典表可以看出,贷前信用评分score在客户综合风险的衡量维度上,可以很好的量化出客户之间的差异,从而在业务理解方面可实现客户的有效分类,因此我们将根据特征score来进行分析。这里需要注意的是,特征label(贷后逾期状态)虽然能够直接体现客户的风险程度,但将客群仅分为好坏2个分类对客户精细化管理的效果欠佳。在确定了客户分类的特征指标score之后,接下来需要明确的重点是围绕特征划分区间的具体标准。由于特征score的含义是信用风险评分,且样本观测均有好坏表现的标签label(0/1),因此可以通过不同分数区间的坏账率大小来实现客群分类。为了更全面描述信用评分的数据分布趋势,以及连续区间的坏账率变化情况,我们通过特征分箱的思想,将连续型的信用评分进行离散化,具体实现过程详见知识星球代码详情。,输出结果如图7所示。
?
编辑
添加图片注释,不超过 140 字(可选)
图7 评分离散化结果
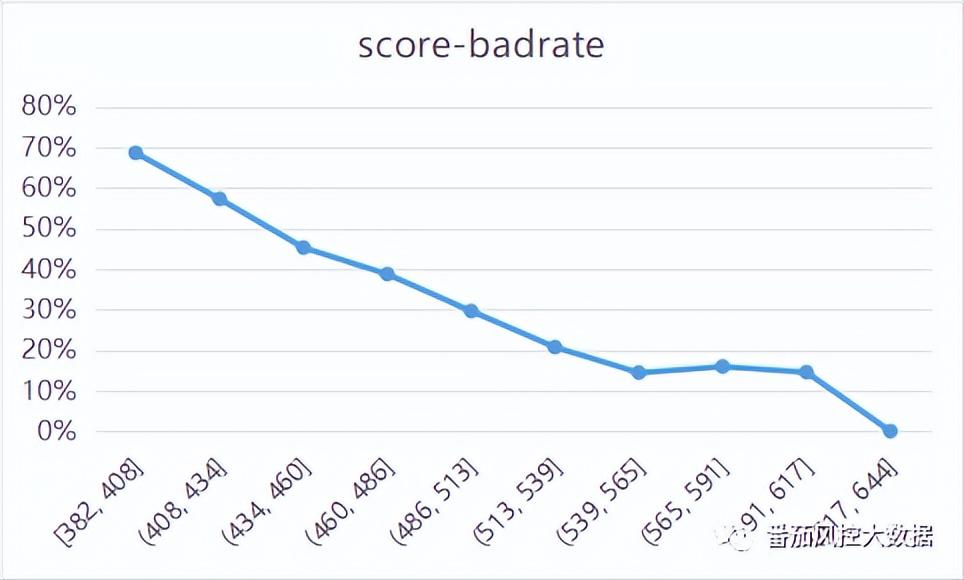
对于上图的评分分布,我们通过连续区间的数据表现可知,随着信用评分(score)的不断升高,坏账率(badrate)逐渐降低,具体分布如图8所示,单调性趋势较好,可以直接说明信用评分对用户风险的区分度效果是比较好的。
?
编辑
添加图片注释,不超过 140 字(可选)
图8 评分数据表现
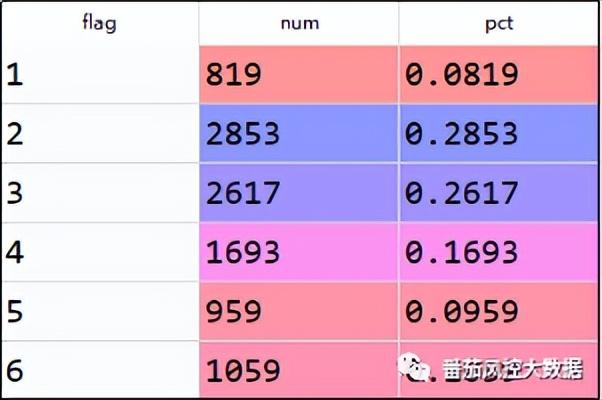
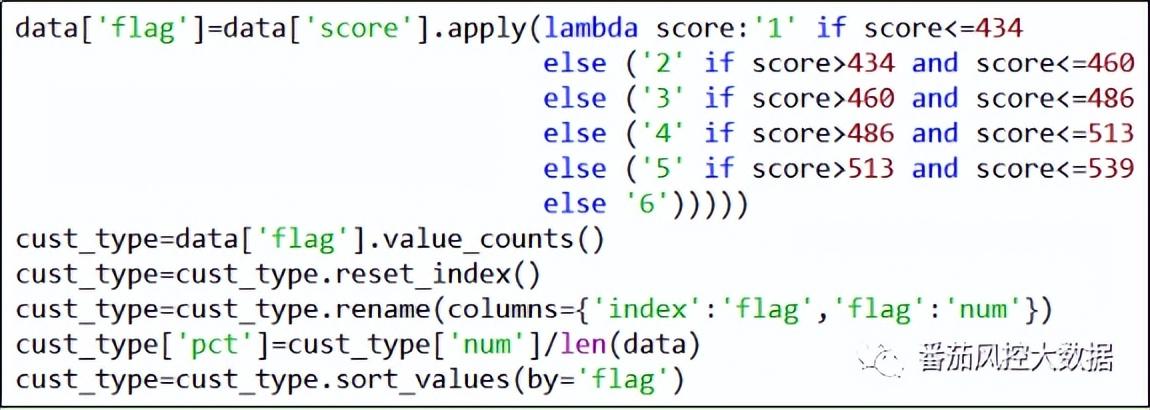
根据评分score与坏账badrate的分布趋势,我们考虑将badrate较为接近的评分区间作为同一类别,同时结合区间样本量大小,将占比较大者单独成箱,占比较小着多箱合并。按照以上逻辑标准,围绕上图的客户评分表现结果,这里考虑将客户群体划分为6个类别,分别为:[382,434]、(434,460]、(460,486]、(486,513]、(513,539]、(539,644]。因此,客户群体通过信用评分score细分为6类,这里采用flag=1~6来表示,具体实现过程详见知识星球代码详情。,客户分类的频数分布如图10所示。
?
编辑
添加图片注释,不超过 140 字(可选)
图10 客户分类分布
4、客户画像方案与实现
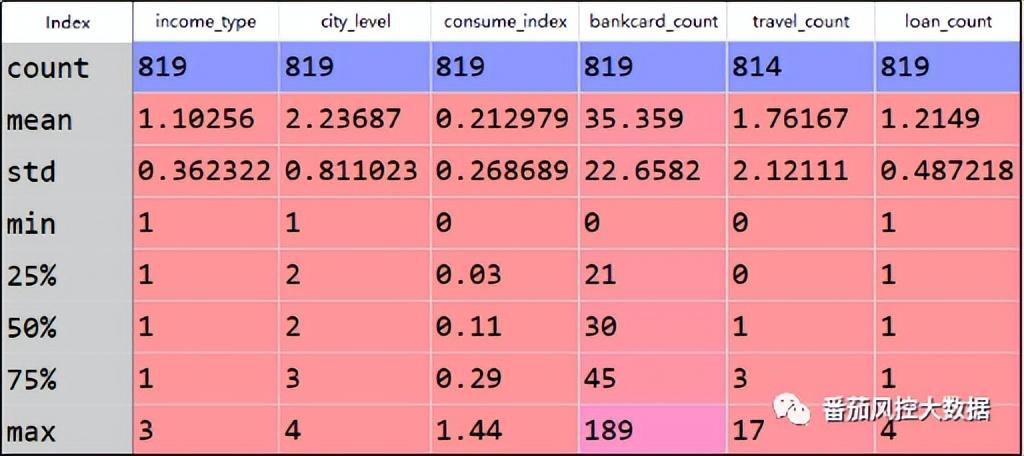
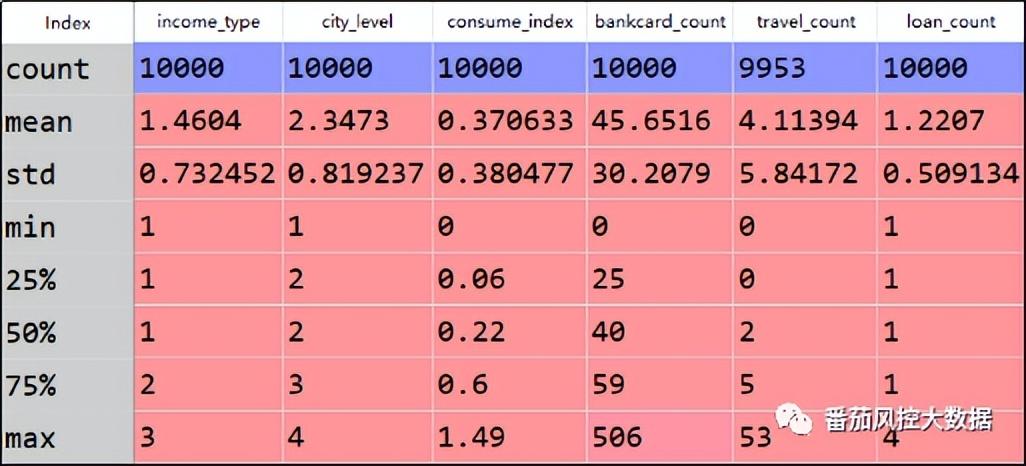
根据客户的信用风险程度高低,我们完成了客户群体的有效分类,接下来围绕每类客群的分布特征进行画像描述。虽然实例样本的特征包含8个,但字段score、label已作为客户分类的依据,因此客户画像的描述性特征将选取其他6个字段。在实际场景中,若分析变量池的字段较多,必然会选取业务解释性较强的部分特征来描述分析。样本群体分布的可解释性维度,可以优先考虑描述性统计值,例如频数、占比、平均值、最大值、最小值等,不仅便于业务理解,而且易于特征描述,因此这里通过此种方式来实现客户画像。为了快速得到各类客群的常见统计值,我们在Python环境中采用describe()函数来完成。针对某一类客群(以flag=1举例)的具体实现过程为data[data['flag']=='1'].drop(columns=['score','label']).describe(),结果如图11所示。为了将此客群与整体客群对比,我们输出全量样本的分布,具体如图12所示。
?
编辑
添加图片注释,不超过 140 字(可选)
图11客群1特征分布
?
编辑
添加图片注释,不超过 140 字(可选)
图12 全量客群特征分布
针对上图分析结果,我们重点分析count、mean、max、min等指标,这里简要描述下客群1(flag=1)的分布特点:客户群体1的数量为819,占全量样本的8.19%;平均月收入等级为L1;居住城市平均等级为B;消费能力整体系数为0.21,相比全量客群的平均系数(0.37)偏低;近12个月银行卡转账次数平均为35次,也低全量客群情况(约46次);近3个月航旅出行次数平均接近2次,明显低于全量客群的平均4次;近6个月申请贷款失败次数约为1次。这里可以初步看出,客群1的整体消费能力一般,且航旅出行的偏好程度较低。对于其他类型客群,都可以按照以上分析思路来描述客户画像,以此来了解每类客户的特点,为风险控制或精准营销等策略提供客观的信息参考。综合以上内容介绍,我们围绕一批存量客户样本,依次实现了客户分类与客户画像,较好的分析描述出客群的分布特点。此外,本文实例的客户分类,由于信用风险评分的量化,也可以理解为客户分层,但分层是分类的一种情况,可以体现出客群之间的比较差异,但需要明确的是,客户分类不一定要客户分层,但客户分层必然是客户分类。例如,通过机器学习的无监督聚类算法得到的客户分类,是一种非分层的客户分类,而采用有监督多分类模型实现的客户价值挖掘,则属于客户分层的情况。对于客户群体的分类或分层需求,具体需要结合实际业务场景。针对本文介绍的客户分类与客户画像,为了便于大家对此有进一步的理解与熟悉,本文额外附带了与以上内容同步的Python代码与样本数据,供大家参考学习,详情请移至知识星球查看相关内容。
关于DuDuTalk: DuDuTalk是武汉赛思云科技有限公司打造的语音数据驱动的一站式智能销售赋能AI-SaaS平台。通过智能硬件(IOT)、AI引擎、机器学习、NLP、文本数据挖掘等技术,为企业提供覆盖移动通话、现场沟通等全场景语音采集、识别、质检、分析等服务。让销售与客户互动全过程数字化、可视化、智能化,用科学的方式实现对销售团队的个性化赋能,让每个人都成为“顶级销售”。


